Smart MPC®
Smart MPC®
独自のPhysical AI。PID制御より賢く、強化学習より実用的
Smart MPC®とは
Smart MPC®は、モデル予測制御(Model Predictive Control)と機械学習(Machine Learning)を組み合わせたPhysical AI(最適制御AI)です。
モデル予測制御の長所を引き継ぎつつ、その欠点であるモデリングの難しさを機械学習によるデータドリブンな方法で解決します。
この技術によって、データを取る環境さえ用意することが出来れば、導入コストが高いモデル予測制御を比較的簡単に運用可能になります。
Smart MPC®は、常に最新のデータに基づいてプラントモデルをアップデートし続けるため、経年劣化や設備更新に伴う制御性能の低下にも柔軟に対応可能です。
従来は人手に頼っていた制御操作やチューニングも自動化され、安定した性能を維持しながら、運用負荷の軽減を実現します。
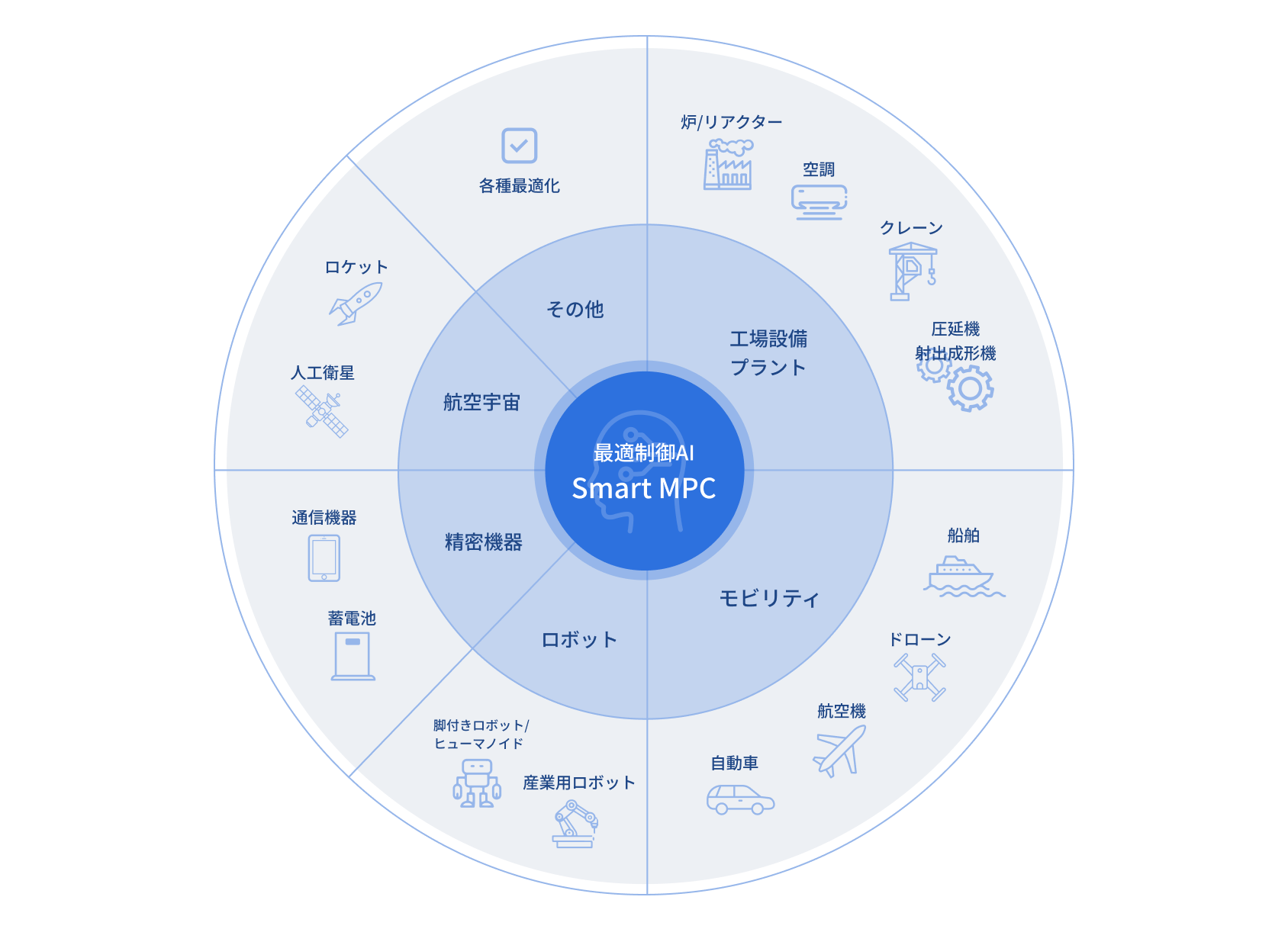
下図は、Smart MPC®がすでに活用されている、あるいは今後適用可能な領域を示した例です。工場設備やモビリティ、ロボット、航空宇宙といった幅広い分野・機器に対応可能です。


アーキテクチャ
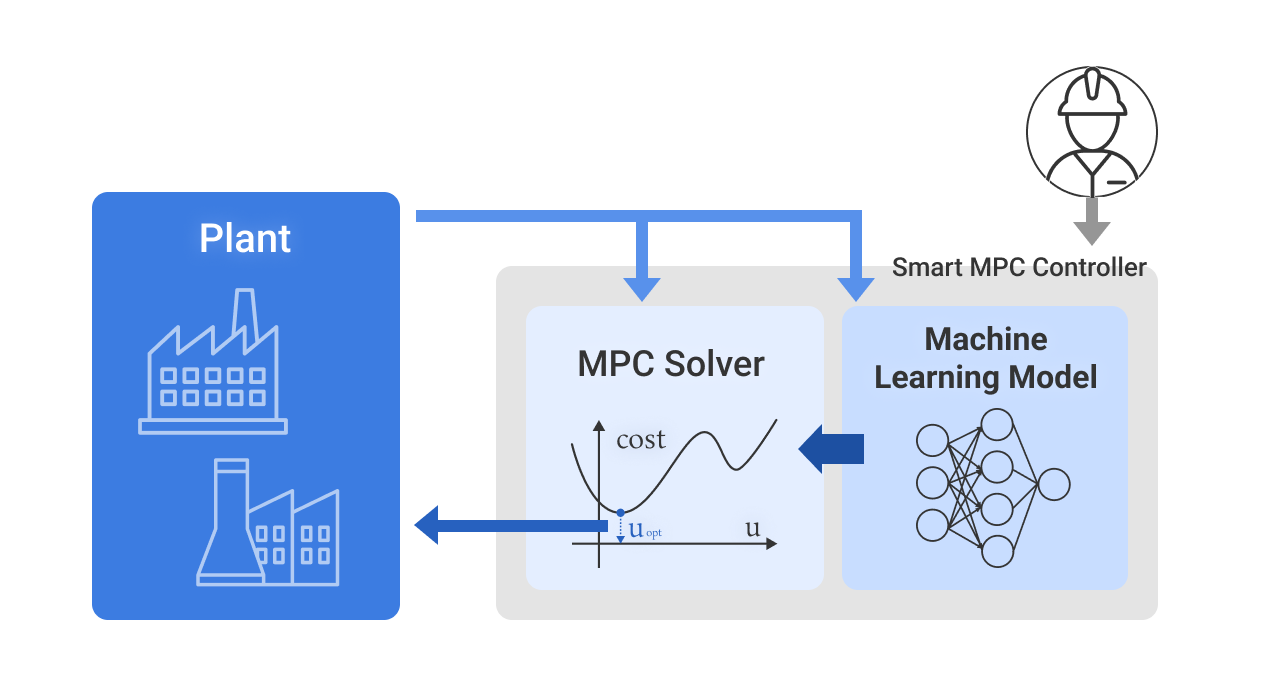
制御システムは制御対象(プラント等)と制御器の2つの要素から構成されています。
制御器の中にはプラントのダイナミクスを模倣するための機械学習モデルと、
MPC(モデル予測制御)に用いるための数理最適化ソルバーが存在します。
機械学習で得られたモデルはMPCの計算に使われ、毎ステップ(例えば1秒ごと)に
最適な制御入力 \( u_{\mathrm{opt}} \) を計算し、プラントに渡します。
倒立振子による実証実験
以下の動画は、Smart MPC® によって倒立振子を「学習しながらリアルタイム制御」している様子を収めたものです。
本実験では、各種パラメータを適当に設定した場合でも、わずか数エピソードで学習が収束し、ポールを安定して立て続けることに成功しました。
強化学習との比較
Smart MPC®はデータからモデルを構築・学習しながら、上記のMPCのアルゴリズムによって制御を行います。 一方でAlphaGoやDQNのような(モデルフリーの)強化学習には、モデルという概念が存在せず、ダイナミクスの学習と行動の決定はすべてQ関数に押し込められています。
本来、状態の価値がわかることと、未来が予測できるかどうかということは別問題であり、これらは分割して解くことが可能であると考えられます。 強化学習を難しくしている原因の一つが、この2つの異なる問題を一気に解こうとしているためであり、Smart MPCではこれらを個別に解くことで学習を著しく簡単かつ安定にすることが出来ました。
一方で、Smart MPC®は評価関数は別個与えてやる必要があるため、評価関数が比較的自明に与えられる問題、例えば温度の乖離やエネルギーの消費量など、であれば適用可能ですが、それが不可能な問題、例えば囲碁や将棋など状態の評価自体が最も重要である問題に対しては直接的には使うことが出来ません。 Bonanzaメソッドのように過去のデータから逆最適化問題を解くことで評価関数を構成することは可能ですが、このタイプの問題には強化学習を使うことが最適であると思われます。
PID制御との比較
PID制御は現代において最も使われている制御手法であり、多くのプラントや機械の制御に使われています。 非常に単純なアルゴリズムであり挙動が理解しやすいため現場で作業者が調整を行いやすいというメリットがある一方で、以下ような欠点を持ちます。
- ・一入力一出力(SISO)系しか扱えない。
- ・拘束条件を扱えない。
- ・学習機能はなく、すべて人間が調整する。
- ・パラメータの調整は系統的に行うことは難しく、一般的に勘と経験に基づいて行われている。
- ・根本的にむだ時間に弱く、ハンチングやオーバーシュートを防ぐためにはスミス補償器のような補助的な機器を用いる必要がある。これはPIDの長所である理解のしやすさを損なわせるものである。
- ・最適性を保証できない。
Smart MPC®は上記すべての欠点を克服することが可能であり、一方でPID制御に決して劣らない手軽さやわかりやすさを備えています。
